아주대학교(이하 아주대) 조현석(소웨) 교수와 김희규(인공지능·석사 2학기) 학우가 언어모델의 성능을 보존시키는 선택적 혐오표현 완화기술을 개발했다. 이는 ‘GTA: Gated Toxicity Avoidance for LM Performance Preservation’라는 논문으로 지난해 12월 싱가포르에서 열린 자연어처리 분야 국제학술대회 ‘EMNLP 2023’에서 발표됐다.
파란학기제에서 시작된 개발
김 학우는 아주대의 파란학기제에 참여해 한국어 생성형 언어모델을 개발했다. 하지만 해당 모델의 텍스트 생성에서 특정 인물에 대한 비하 발언이나 욕설 등을 포함한 혐오표현이 나타나 모델의 공개에 어려움을 겪었다. 실제로 마이크로소프트에서 2016년에 발표한 인공지능 채팅봇 ‘테이’는 혐오표현을 학습하고 생성해 16시간 만에 이용이 중단됐다. 이처럼 생성형 언어모델에서 혐오표현을 완화하는 기술은 필수적인 요소다. 그러나 언어모델의 혐오표현을 제거하기 위해 적용한 기술이 언어모델의 성능을 저해한다는 문제가 있었다. 이를 계기로 언어모델의 성능을 저해하지 않는 혐오표현 완화기술에 대한 연구를 시작했다.
언어모델의 텍스트 생성
‘토큰’은 공백이나 구두점 등으로 분리된 최소 단위다. 이는 텍스트를 구성하는 최소 단위를 말한다. 언어모델이 텍스트를 생성할 때는 결과 텍스트를 한꺼번에 생성하지 않고 토큰 단위로 생성한다. 언어모델은 단어 집합에서 각 토큰이 생성될 확률을 계산한다. 이때 확률이 가장 높은 토큰이 다음에 생성된다. 기존의 대표적인 혐오표현 완화기술은 ‘CTG(Controllable Text Generation)’ 방식으로 토큰을 생성할 때 기존 입력 내용에 맞는 다른 토큰으로 바꿔준다. CTG 방법은 개별 토큰이 생성될 때마다 혐오표현 완화기술을 적용한다.
기존 CTG 방식의 언어모델 성능 저하
이 논문은 CTG 방식으로 인한 성능 저하 요인을 규명하고 이를 보완한 방식을 제안한 최초의 논문이다. 기존 혐오표현 완화기술은 언어모델과 CTG만으로 구성됐다. 이때 CTG는 용량이 크고 계산량이 많다. 또한 인공지능이 학습한 무수한 데이터에 대해 일일이 혐오표현 완화기술이 적용된다. 때문에 토큰의 유해성에 대한 판단 없이 매번 CTG 기술이 적용되는 기존 방식에서는 언어모델의 텍스트 생성 시간이 크게 지연됐다. 이 과정에서 ‘추론 오버헤드(Inference overhead)’ 현상이 발생한다. 이 현상은 CTG 방식이 토큰 생성 과정에서 필요한 추론 시간과 메모리를 추가적으로 요구한다는 것이다. 때문에 CTG를 적용한 언어모델은 CTG를 적용하지 않은 언어모델에 비해 평균 6.75배 느려졌다.
CTG는 기본적으로 혐오표현이 완전히 없는 데이터에 가까워지도록 언어모델을 바꾼다. 혐오표현이 많은 데이터의 경우 사용자의 감정이 부정적이거나 특정 정치적인 주제에 대한 내용이 포함된 경우가 많다. 이때 CTG는 언어모델이 텍스트에 담겨 있는 혐오표현만을 피하도록 하는 것이 아니다. 특정 주제나 부정적인 감정 자체를 생성하지 않는 일종의 ‘편향(bias)’ 현상이 발생한다. 때문에 언어모델의 문법성과 유창성 그리고 주제 일치성에서 성능 저하가 나타난다. 예를 들어 영화에 대해 부정적으로 평가하는 상황에서 ‘I watched a horror movie. It was so’라는 문장 다음 생성될 토큰에 ‘good’와 ‘bad’ 그리고 ‘stupid’의 세 가지 데이터가 있다고 가정한다. 이때 부정적인 표현에는 ‘bad’와 ‘stupid’가 있지만 ‘stupid’는 유해성까지 포함한 데이터다. 비슷하게 부정적 의미를 내포하고 있는 ‘bad’와 ‘stupid’가 혼용되는 경우가 많기에 유해성을 포함하지 않은 ‘bad’까지 생성되지 않는 것이다. 이에 전혀 의도하지 않았던 긍정적인 토큰 ‘good’이 더 자주 생성되는 결과가 나타난다. CTG는 이런 방식으로 부정적인 텍스트 자체를 덜 생산하고 긍정적인 텍스트를 많이 생성하도록 장려한다. 때문에 의도와는 다른 텍스트가 생성되는 경우가 발생한다.
언어모델의 성능을 보존할 수 있는 새로운 기술
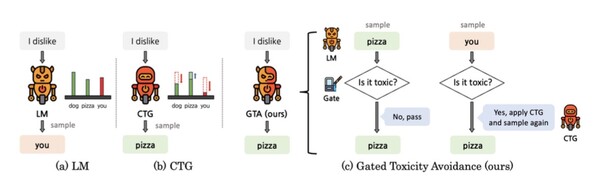
김 학우는 기존 방식의 텍스트 생성 시간 지연과 성능 저해를 보완한 GTA(Gated Toxicity Avoidance) 방법을 제안했다. 이는 기존의 언어모델과 CTG에 더해 새로운 혐오표현 탐지기(Classifier)를 추가한 것이다. 이러한 혐오표현 탐지 모델을 ‘게이트(Gate)’라고 한다. 즉 새로운 모듈이 추가된 ‘선택적 완화 모델’을 제안한 것이다.
게이트에 의해 언어모델의 텍스트에서 혐오표현이 생성됐다고 판단했을 때만 CTG가 작동하게 된다. 때문에 언어모델의 작동 시간을 지연시키는 CTG가 동작하는 횟수가 줄어들고 그만큼 추론 오버헤드가 줄어들며 언어모델의 텍스트 생성 속도가 빨라진다.
또한 게이트가 생성될 토큰의 유해성을 판단해 기존 언어모델과 비교했을 때 유해한 표현이 생성될 확률은 낮춰주고 유해하지 않은 토큰이 생성될 확률들은 높여준다. 게이트 모델이 샘플 토큰의 유해성을 판단한 후 유해하지 않다고 판단되면 토큰으로 생성한다. 그다음 다시 샘플링을 진행해 다음에 등장할 토큰을 생성한다. 이는 기존의 방식과 비교했을 때 문법성과 유창성 그리고 주제 일치성에서의 성능 저하가 발생하지 않는다.
앞으로의 연구가 나아갈 길
이번 논문에서 제안한 기술은 기존의 기술에 비해 언어모델의 생성 시간이 빠름에도 여전히 오버헤드가 존재한다. 때문에 김 학우는 언어모델과 함께 CTG와 게이트를 한 번에 수행할 수 있는 모델을 개발하기 위한 추가적인 연구를 진행하고 있다. 이 기술을 개발해 현재 상용화된 GPT 서비스에 적용한다면 큰 성과로 이어질 수 있다.
김 학우는 “파란학기제로 시작한 연구가 논문 집필까지 이어지게 됐고 이를 통해 EMNLP 2023 학회에도 다녀올 수 있게 돼서 영광이다”며 연구 소회를 밝혔다. 이어 김 학우는 아주대 학우들에게 “프로젝트를 진행할 의향이 있으신 분들은 프로젝트를 연구로 이어갈 수 있는 기회로 삼길 권한다”고 말했다.
Tip.
언어모델: 언어를 다루는 인공지능 모델
오버헤드: 특정한 목표를 달성하기 위해 간접적 혹은 추가로 요구되는 ▲대역폭 ▲메모리 ▲시간 혹은 다른 컴퓨터 자원